
This article is based on the first part of a presentation delivered by the author and Hans Hillen at CSUN 2024 Conference. It includes content that was not used in the conference presentation due to time constraints. You can also access all the slides used in the presentation.
The focus of this article is to explore the role of AI in enhancing web accessibility. Inevitably, this will involve a certain amount of discussion of potentialities – what AI could do – but I especially want to look at the here and now – what AI can do.
I want to do this by looking at the intersection of AI and web accessibility from the perspectives of:
- Web developers, designers and authors who create web content
- Digital accessibility professionals who try to make web content accessible
- People with disabilities who try to access web content
AI Definition
My plan is to explore some practical examples of the ways in which AI can be used by these three groups of people.
Having used the term four times just in our opening sentences, and being likely to use it many more times in the rest of this presentation, let’s first establish what we’re talking about when we say “AI”.
The letters, of course, stand for Artificial Intelligence, but what exactly does that mean? Well, one definition is:
“Artificial Intelligence (AI) refers to the development of computer systems that can perform tasks that typically require human intelligence.
These tasks include learning, reasoning, problem-solving, understanding natural language, speech recognition, and visual perception.
AI aims to create machines or software that can mimic cognitive functions associated with human intelligence and, in some cases, surpass human capabilities in specific domains.”
I like this definition because it focuses on tasks that AI can perform – what it can do rather than what it is – and that it aims to mimic human cognitive functions.
I don’t suppose it will surprise anyone that this definition was supplied by ChatGPT.
If you don’t know what ChatGPT is, it’s:
“… a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture.
GPT-3.5, like its predecessors, is designed to understand and generate human-like text based on the input it receives.
“ChatGPT” specifically refers to instances of the GPT model that are fine-tuned for generating conversational responses.”
And, yes, that definition was also supplied by ChatGPT.
AI Technologies
AI can take many different forms, some of which we’ll be exploring today. ChatGPT is an example of Natural Language Processing, which enables conversational exchanges between humans and machines. Some other types of AI functionality that will come up in our discussions today include:
- Machine Learning uses structured data and algorithms to imitate the way humans learn
- Natural Language Processing allows computers to engage with humans in conversational language
- Large Language Models work off very large datasets to produce content humans can comprehend
- Computer Vision enables computers to analyze, recognize and describe images in human terms
- Deep Learning can learn from unstructured data, increasing scale, depth and complexity
Where needed, I’ll explain these terms as they come up in the examples we’ll be looking at in this article, which include:
- User Interface Customization
- Automated Code Remediation
- User Simulation
- Image Analysis
- Visual Description
- Automatic Alt Text Generation
- Automatic Captioning
- Automatic Speech Recognition
- Predictive Text
- Text-to-Speech
- Speech-to-Text
- Overlays
You knew that last one was coming, didn’t you?
In fact, we’ll begin with the digital elephant in the virtual room.
This article was always going to have elements of the good, the bad and the ugly, so let’s start with – by reputation, at least – the ugly.
Overlays
So, what exactly is an overlay?
At its most literal, an overlay is simply something laid over something else. In digital technology and web content, an overlay is a piece of software laid over a website or app to perform a specific function.
We use them all the time. A pop-dialog is an overlay.
When you click that calendar icon and it expands into a box with a date picker, that’s an overlay.
The floating chat symbol at bottom right is an overlay and when you activate it it expands into a bigger overlay with a chat interface.
Even when you hover over or focus on an element with a title attribute and a tooltip becomes visible – that’s an overlay.
In themselves, as long as they’re accessible – keyboard operable, within the viewport, persistent, dismissible, etc – there’s nothing inherently wrong with using overlays.
In a digital accessibility context, however, some overlays make very specific claims, including being able to use automated tools to assess web content for WCAG conformance and then automatically implement code changes or new code that will guarantee conformance, with the site owner needing to do no more than install a widget.
There are variations on this. Some overlays present an icon that the end user can activate to set a series of user preferences: text size, contrast, etc.
Some generate a report that the site owner can use to manually implement site improvements.
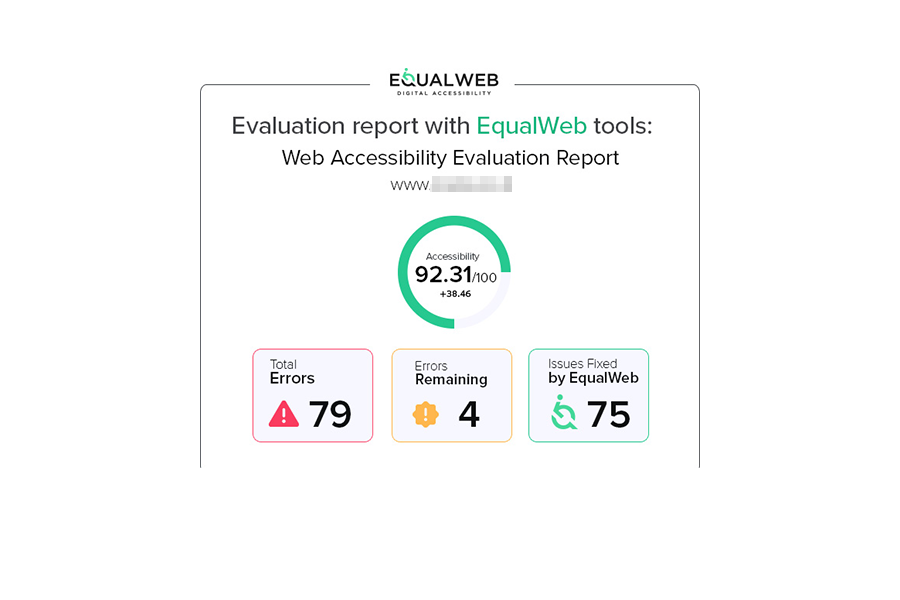
They all fall under the broad title of “digital accessibility overlays” and they are what we’ll refer to as overlays for the purpose of this article.
There has been a great deal of criticism directed towards overlays, which can be briefly summarized as
- The modifications that overlays implement cannot guarantee full conformance with WCAG, because no automated tool can.
- The modifications that overlays implement are often unreliable, ineffective, and / or create other accessibility issues than the ones they address.
- The modifications that overlays make often interfere with assistive technologies and accessibility settings already in use.
- The use of an overlay may create non-compliance with privacy regulations.
These are serious considerations, and more detail is available at the Overlay Fact Sheet website.
This article is about AI, so we’re going to focus on overlays that use – or claim to use – Artificial Intelligence. And there are a few!
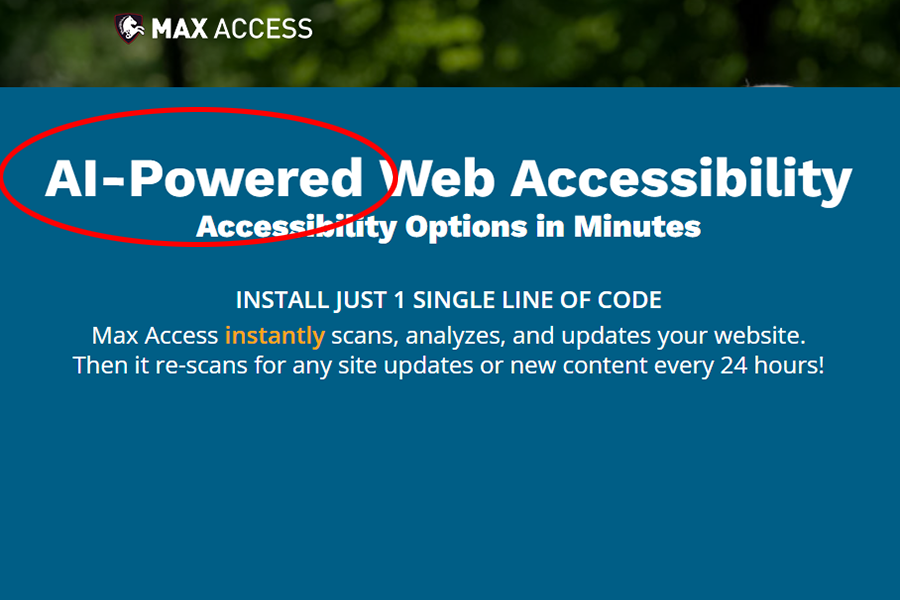
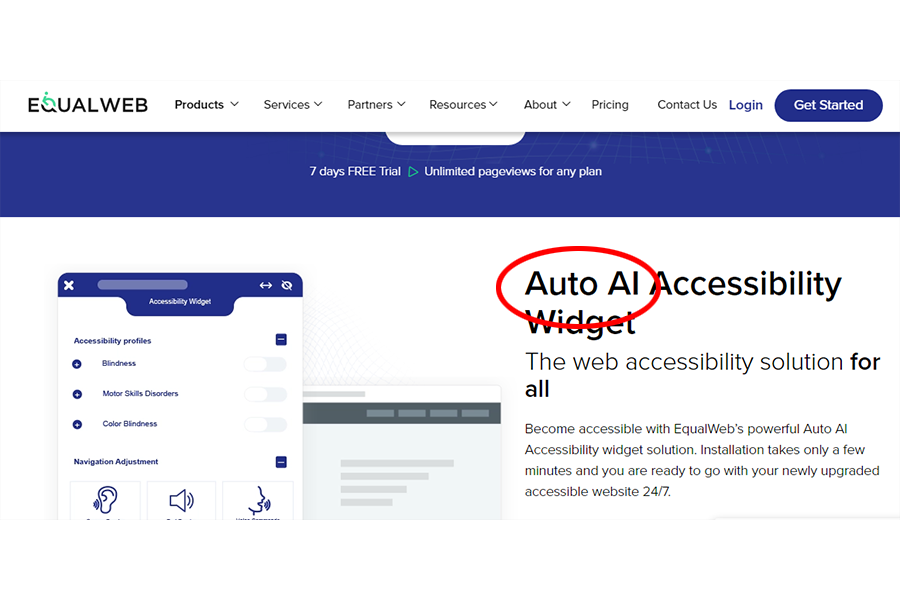
While many tools that could be called overlays claim to be “AI-powered”, by no means all do, and many automated testing tools that use AI could not be called overlays.
In fact, very few “AI-powered” overlays are very clear about exactly what Artificial Intelligence technologies they use, and how.
Let’s take a look at one that does go into some detail: accessiBe.
This makes a good example, because:
- it’s the market leader in terms of sales and implementations (it’s not the only one that claims this, though)
- it’s more explicit than most in its explanations of how it uses AI in overlays
- it uses AI in different ways in different products
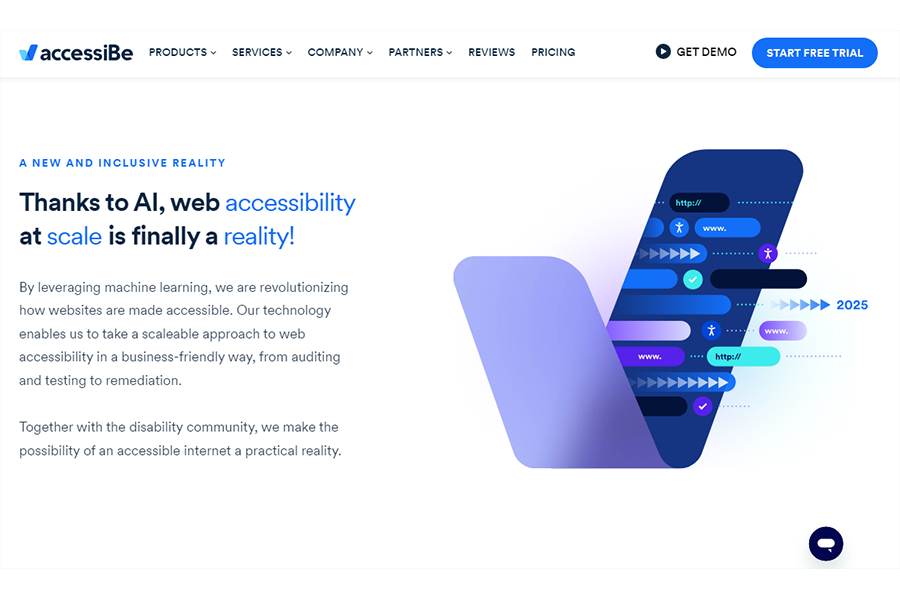
The accessiBe home page tells us that “Thanks to AI, web accessibility at scale is finally a reality.”
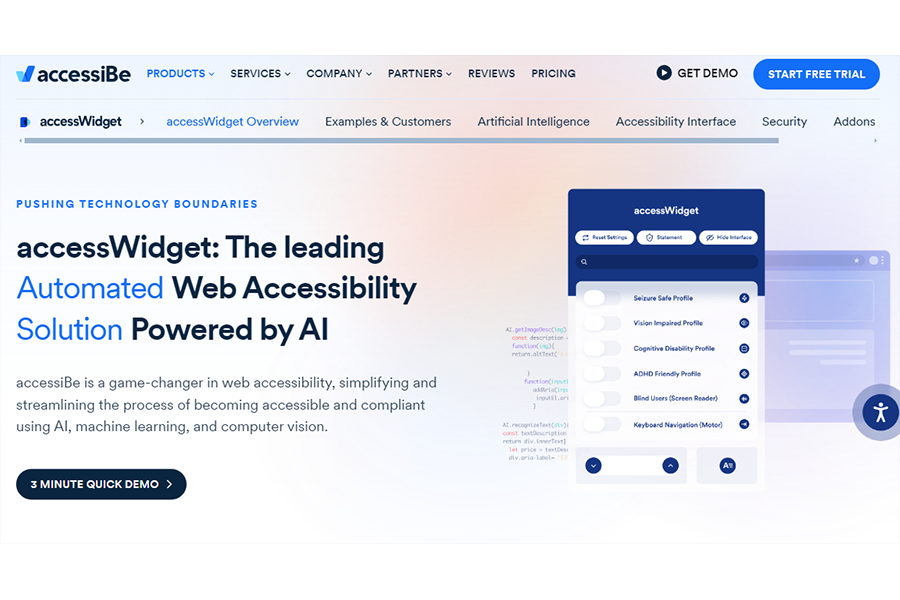
Its accessWidget claims to be “The leading Automated Web Accessibility Solution Powered by AI”.
“accessiBe is a game-changer in web accessibility, simplifying and streamlining the process of becoming accessible and compliant using AI, machine learning, and computer vision.”
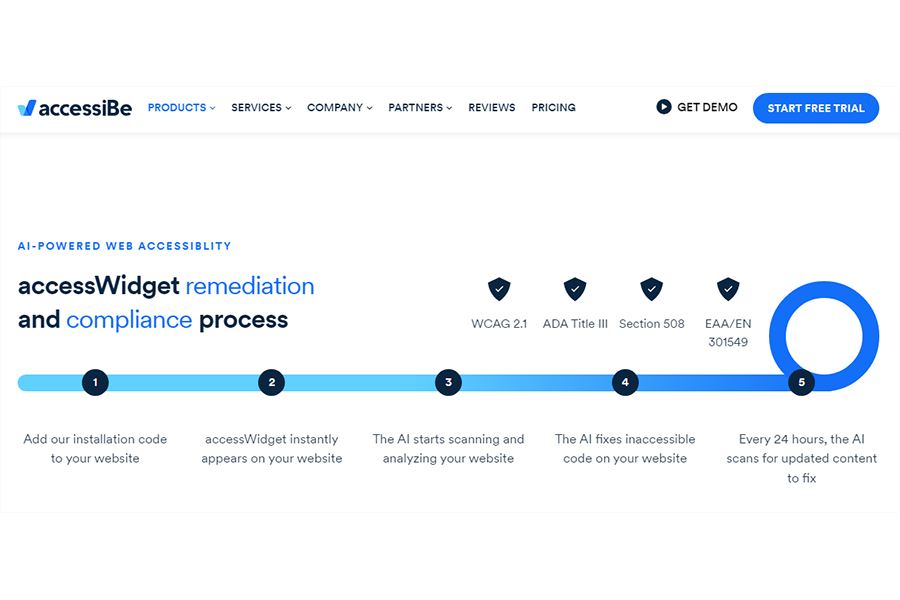
- “Add our installation code to your website
- accessWidget instantly appears on your website
- The AI starts scanning and analyzing your website
- The AI fixes inaccessible code on your website
- Every 24 hours, the AI scans for updated content to fix”
How does the AI achieve this?

The claim is “accessiBe’s AI is responsible for handling the more complex accessibility adjustments such as screen-reader optimization and keyboard navigation. The automated nature allows for these backend adjustments to be done efficiently, affordably, and within reasonable timeframes.”
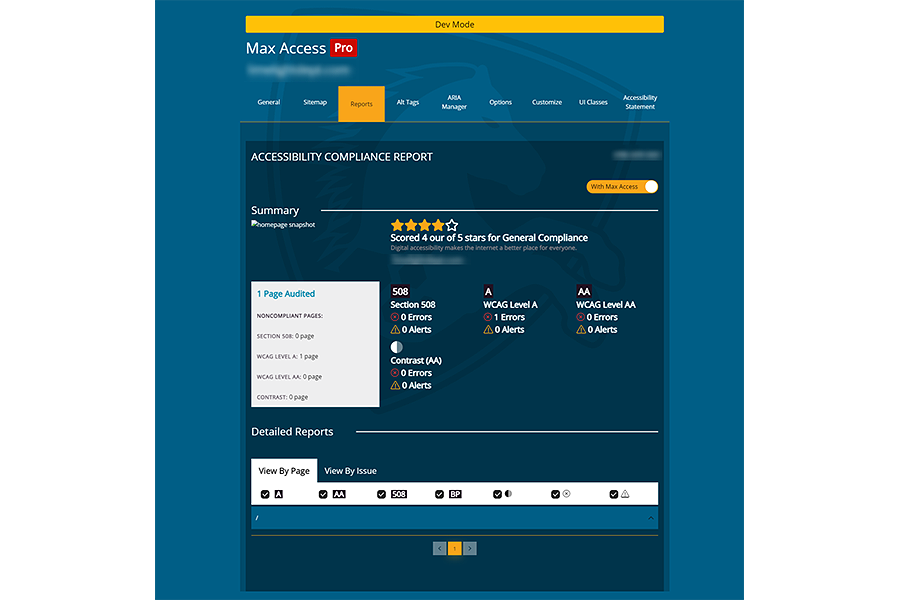
The accessWidget product actually consist of two parts, one a process that operates in the background, the other a widget on the user interface that a user can configure.
Under the heading “Computer vision applied to accessibility”, accessiBe tells us:
“accessWidget scans all images on the site. Whenever alternative text (Alt attributes) is missing, it will extract the embedded text using OCR and learn the objects that comprise the image using IRIS technology.”
OCR is Optical Character Recognition, a technology that’s been around for many years and is used in many contexts to turn images of text, such as scanned documents or on web pages, into actual text that can then be manipulated. It’s probably one of the oldest technologies that can be described as AI.
I had to dig beyond the accessiBe website to find out what “IRIS technology” is. It refers to an advanced form of Machine Vision using Deep Learning and Neural Networks to identify image content (not to be confused with “iris recognition”, which is about scanning eyeballs to authenticate identity).
Basically, IRIS is trained off a database of images that must be sufficiently representative (in other words, huge) to “interpret” and “recognize” images. How it does this is not clear, and certainly not explained by accessiBe.
“Then, accessWidget will automatically provide accurate and elaborate alternative text to these images. When a blind user enters a site, their screen reader will rely on these descriptions to communicate what is on the page.”
The claim is that “These adjustments are compatible with popular screen readers such as JAWS, NVDA, VoiceOver, and TalkBack”, a claim some dispute.
An Accessibility Statement notes that the client website’s accessibility is managed by accessiBe, with an aim to “adhere as strictly as possible to the World Wide Web Consortium’s (W3C) Web Content Accessibility Guidelines 2.1 (WCAG 2.1) at the AA level”.
The statement makes a point of saying that the website utilizes “an AI-based application that runs in the background and optimizes its accessibility level constantly. This application remediates the website’s HTML, adapts its functionality and behavior for screen-readers used by blind users, and for keyboard functions used by individuals with motor impairments”.
The statement explains how the website is optimized for screen reader users: “As soon as a user with a screen-reader enters your site, they immediately receive a prompt to enter the Screen-Reader Profile so they can browse and operate [the] site effectively.”
This appears to address one of the main complaints about accessibility overlays, that they degrade the site experience for people already using a screen reader. It does, though, raise the question of how screen reader use is detected, and whether that is an invasion of the user’s privacy.
There is further detail about how a process is run to learn “the website’s components from top to bottom”, applying ARIA where needed and using “image-object-recognition” to add missing alt text and OCR to extract text embedded in images.
Which specific AI technologies are used to ensure keyboard accessibility is even less clear.
“accessWidget makes websites navigable by keyboard. By using ARIA attributes and contextual understanding AI engine, accessWidget makes the necessary adjustments throughout the website’s code. People with motor impairments can use the keys to do everything from closing popups and forms to opening drop downs and menus.”
So, accessWidget uses an automated checking tool to find accessibility issues on functional elements, and then uses JavaScript to apply ARIA roles, attributes, and labels to make those elements keyboard accessible. What role AI plays in this is not specified.
With all this going on in the background, this part of accessWidget might be better described as an “underlay” rather than an overlay.

As well as this, there is also a widget in accessWidget, which is installed on the user interface. This has a number of generic profiles that can be adopted and customized, or turned off to support purely custom adjustments. If a user has already configured a reduce motion setting at the operating system level, that does not have to be activated in accessWidget.
It seems accessiBe has learned a lot from the poor publicity it received in its earlier incarnations and, presumably, its relationship with the National Federation of the Blind, to make its accessWidget product more user-controlled and responsive to user choices. The logic seems to be “Use AI technologies in background, and let the user configure the front end widget as they wish”.
accessiBe also has another product called accessFlow, aimed at helping web developers to “incorporate web accessibility natively into your websites by treating it as another pillar to address while developing for the web. Just like security, performance and observability are application essentials, accessibility now gets the same treatment. With accessFlow, you can treat accessibility as a material part of your software lifecycle without doubling the workload.”
Where does the AI come in?
“accessFlow’s AI behaves like an actual user in the auditing sessions by clicking on buttons, using keyboard combinations, submitting forms, and mimicking other actions while auditing the accessibility and usability of these functionalities.”
That’s a big claim, but accessiBe is not the first to say that AI can be used to simulate user behavior.

“Using accessiBe’s AI technology, accessFlow can automatically recognize elements that no other platform can, like menus, form validations, and page landmarks, and suggest the best practices and approaches to remediate them.”
Ultimately, then, we’re left with one over-arching question regarding the use of AI in digital accessibility overlays.
“Is the claim of some overlays that the use of AI provides fully automated functionality that can identify and remediate all WCAG issues on a website, with no human intervention, valid?”
On the available evidence, the answer has to be “Not completely”, or “Not yet”, or just “No.”
Automatic Captioning
Like optical character recognition, captions have been around for well over a century. Given that the first generation of publicly screened movies were silent, it’s no surprise that caption cards or intertitles were inserted between scenes to convey key dialog and sound effects.

When sound came along, intertitles were no longer needed for the movies, and captioning was pretty much restricted to the subtitling in one language of dialog in delivered in another. These subtitles were typically burned onto the film print, which meant they couldn’t be turned off or adjusted, what we now call open captioning.
It wasn’t until the 1960s, after schools for deaf children called for captioning for educational purposes, that public broadcasters of television felt the urge to meet the needs of deaf and hard-of-hearing viewers by providing captions to popular TV shows. Julia Child’s popular cooking show The French Chef was the first to trial open captions in 1972, dispelling fears they would drive away hearing viewers.

Photo: WGBH
Open captioning was extended to some news and current affairs programs, but really only on federally funded public broadcasters. By the 1980s, technology had advanced to making available closed captions that could be turned on and off, albeit via a relatively expensive decoder, and legislation was introduced mandating the provision of captions for pre-recorded television.
Back in the 1950s and 60s, speech recognition and text-to-speech models were being developed for single-speaker voice recognition with very limited vocabularies. In other words, machines were trained to recognize speech from one specific person – if they only used certain words – and render them as text, laying the foundations for Automatic Speech Recognition (ASR), the basis for automatic captioning of videos.

Photo: Beyond Design
Without getting too technical, development of speech recognition in the 1970s and 80s depended on two factors. One was the advancement of probability logic, where a machine could calculate the likelihood of correctly predicting a word based on other words around it, how well it knows the voice, and its familiarity with language, syntax and grammar. The other factor was computing power. By 1976, the most powerful computer could decode 30 seconds of speech but took 100 minutes to do it.

Photo: Electronic Products
By the 1980s, though, machine vocabularies were larger than those of the average person, and had become speaker-independent, making speech recognition much more reliable and useful.
A big breakthrough came in the 2000s when probability logic was overtaken by the wonderfully named Long Short-Term Memory (LSTM) capabilities, a form of Deep Learning that allows for recall of events such as “hearing” a word from thousands of steps ago. Greater computing power, larger datasets and LSTM brought speech-to-text into the AI family, where it became known as ASR, and the basis for automated captioning functionality currently offered by video providers like YouTube, Vimeo and Facebook.
Photo: Vimeo
A pre-recorded video can be uploaded to one of those services, and service users can activate a Closed Captions control on the user interface to display automatically generated captions.

Photo: Meta
Google made this available on YouTube in 2009. Its media release of the time noted that caption tracks could also be translated into 51 different languages, making video content more widely accessible not only to those with hearing impairments but also to people who spoke languages other than that of the original content.

Photo: YouTube
As well as using ASR to enable auto-captioning, YouTube also introduced auto-alignment, which meant if you already had a transcript to upload with a video, it would use automatic timing to align the transcribed words to the words spoken on the screen.
AI for the win!
Well, nearly.
When Google made this available on YouTube in 2009, even in its moment of automated glory, it had to admit that the quality of its auto-captioning was not always very good.
Photo: New York Times
The New York Times quoted deaf Google engineer Ken Harrenstien as saying at the launch, “Sometimes the auto-captions are good. Sometimes they are not great, but they are better than nothing if you are hearing-impaired or don’t know the language.”
And there’s the rub with ASR. It isn’t very good, and it isn’t getting much better.
And let’s be clear about what we mean by “very good”. There are three ways of measuring caption accuracy.
- Word Error Rate (WER) is a formatting-agnostic measurement, meaning that WER scores do not count errors in capitalization, punctuation, or number formatting. A rating of “99% accurate captions,” means those have a WER of 1%.
- Formatted Error Rate (FER) is the percentage of word errors when formatting elements such as punctuation, grammar, speaker identification, non-speech elements, capitalization, and other notations are taken into account. Since formatting errors are common in ASR transcription, FER percentages tend to be higher than WER.
- The NER model is used to rate live captioning based on a formula that weighs the total number of words (N), edition errors (E) and recognition errors (R) to measure how well meaning is conveyed, which is more inherently subjective than WER or FER.
Since the NER Model focuses on live captioning and is used in a limited number of territories, we’ll put that to one side for the moment.

In the 2023 State of Automatic Speech Recognition report by 3PlayMedia (a vendor of video accessibility services), no automated captioning from ten different vendors achieved a WER of less than 6.86%. Once formatting was taken into account, none of the vendors had an FER of less than 17.2%.
This equates to about one in six words being incorrectly captioned – at best. Some auto-captioning vendors had error rates as high as 42%.
With regard to web content, it should be noted that while standards like WCAG require the provision of captions in some contexts, they have little to say about quality, how accurately captions convey dialog.
In television contexts, though, the FCC is much more specific, requiring 99% accuracy. If that standard was included in WCAG, no web pages with auto-captioned videos would conform.
Some of the specific issues reported with auto-captioning include:
- not distinguishing one speaker from another
- running words together (“uncontrolled euthanasia” instead of “uncontrolled youth in Asia”)
- splitting up words (“contextualize” becomes “con text you’ll eyes”)
- confusing homophones (mixing up “to”, “two”, and “too”)
- not taking context into account (if the preceding words are “he started his daily”, the following word is more likely to be “routine” than “rupee”)
- hallucination (if something sounds like it might be dialog, ASR will make it up, even if it isn’t dialog)
In some ways, AI has made some issues worse. Where earlier forms of automated captioning might admit something is “indecipherable”, AI-powered ASR tends to supply something, even if it is wildly inaccurate.
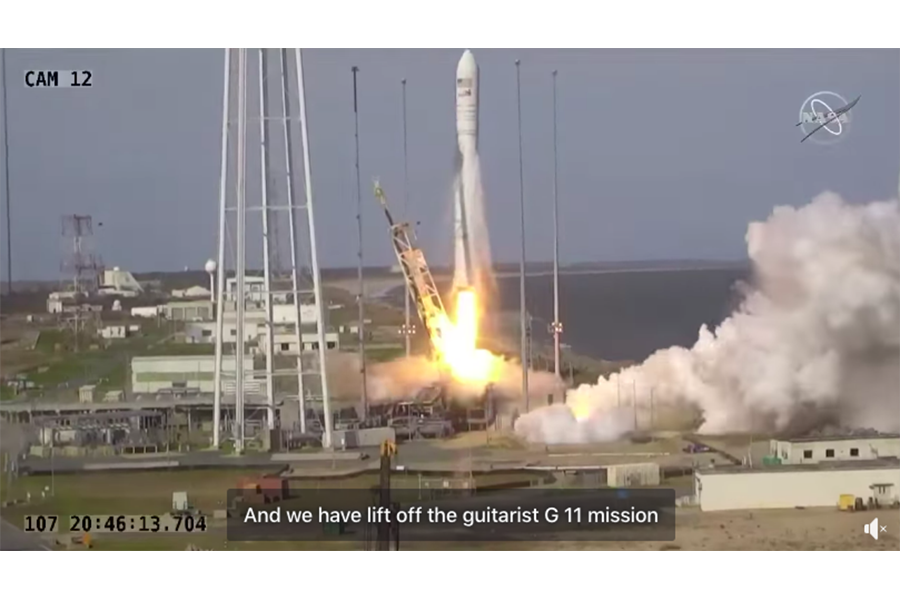
The caption for this screenshot of a video of a NASA rocket launch says, “And we have lift off the guitarist G 11 mission”. What was said was, “And we have lift off of the Antares NG-11 mission.”

In this shot, the caption reads “core pressures Asian looks good”, rather than “core pressurization looks good.”

And this caption says, “Phenomenal”, when it should say, “TVC is nominal”.
Photos: Mashable
It’s entirely possible that some of the current barriers to greater accuracy, such as that ASR engines respond better to a single voice rather than multiple voices, will be overcome but probably not in the very near future.
In the meantime, to get decent captioning, a user has to upload the video, download the automatically generated captions file, edit it for accuracy, and re-upload it. Or pay a commercial service to do it.
It’s interesting that a major provider like Rev.com has developed an automated captioning service alongside its more expensive manual service, but concedes that the manual service is more accurate.

Screenshot: Rev
“Rev offers the most accurate automatic transcription model in the world … and its word error rate is about 14%. That means you can expect about 86% of your transcription to be accurate, on average. If you need higher accuracy rates, you might want to go with human transcription.”
For the foreseeable future, like many forms of AI-powered functionality, a human touch is needed to ensure captioning accuracy.
AI Generated Alt Text
Illustration: Veryfi
Using machines to analyze and report on the content of images is not at all new.
Optical character recognition (OCR) was an outcome of pre-World War I experiments with telegraphy and creating reading devices for the blind.
One of these projects developed the capacity to read printed characters and convert them into telegraphic code.
Another used a handheld scanner that produced a range of audio tones that corresponded to different characters printed on a page.

Photo: Pedersen Recovery
It was Ray Kurzweil in the 1970s who created the breakthrough technology that enabled a machine to read out text content to blind people, combining a flatbed scanner with synthesized text-to-speech.
Over the next few decades, OCR became a standard way for companies to scan documents and store them as text.
In a previous job, I can remember editing the resulting documents to correct errors, often due to the low resolutions of the images that were captured, which made them hard for a human to read, let alone a machine.
Photo: Abbyy
{kind=link}
Nowadays, OCR is a core part of screen reader technology, as well as being used in dozens of applications that require translating a picture of text into text.

Back in the 1970s, some of the same technology was being used to develop Computer Vision (CV), a technological way of analyzing and reporting on the content of a much wider range of images than just text.
It was very much seen as part of the nascent development of AI, automating tasks associated with the human visual system.
Illustration: N-ix
Many of the algorithms developed then are still in use today, such as the ability to discern edges, implied structure, the labeling of lines, and motion estimation in videos.
As more sophisticated algorithms developed, the massive recent increases in datasets and the processing power to analyze them has led to Machine Learning and Deep Learning techniques being applied to Computer Vision to produce truly remarkable advances in image recognition and description.
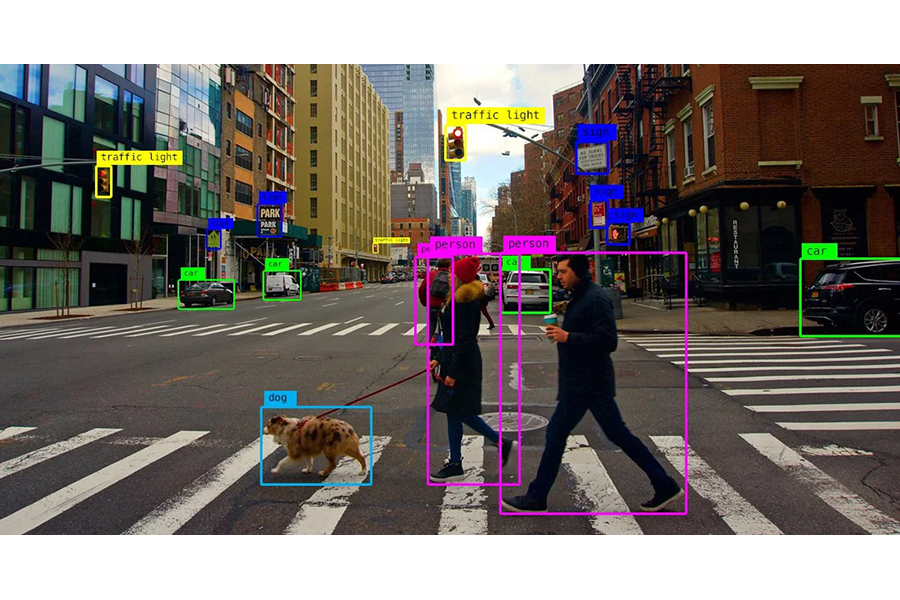
Photo: Algotive
So, CV + ML + DL should produce great alt text, right?
Well, we all realize it’s not that simple.
Producing text that describes an image in an automated, mechanical way is not the whole story of what makes good alternative text for accessibility purposes.
Early efforts revealed limitations in datasets that made machines produce text that was neither accurate nor appropriate. In 2015, Google Photos was rightly criticized for offensive autotagging of photos of African Americans.
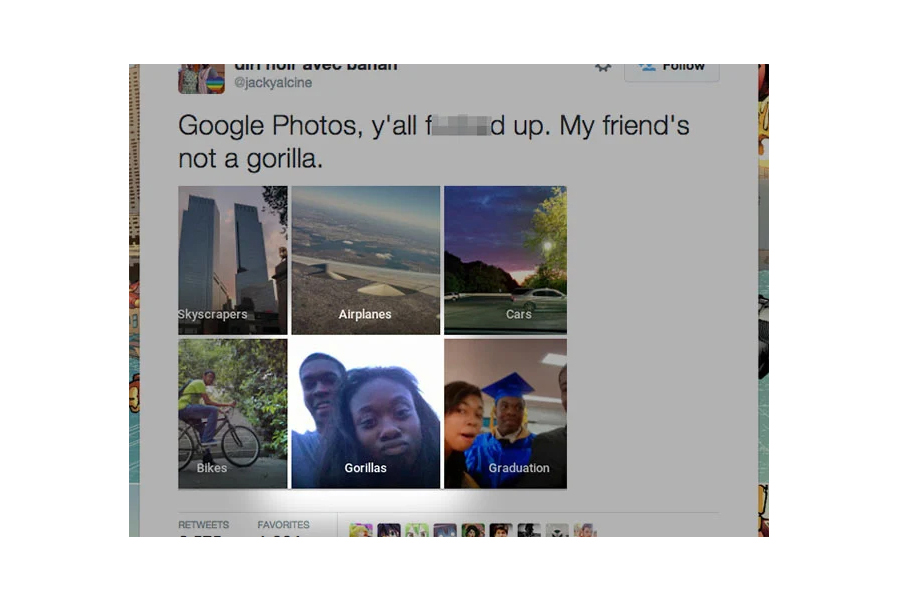
Photo: Peta Pixels
But large datasets and better analysis are improving that greatly.
The frontier we now face is context. Isolating an image from the context of its web content does not produce good alt text.

Photo: Jstor
This image is of an anti-apartheid protest at a US college in 1986.
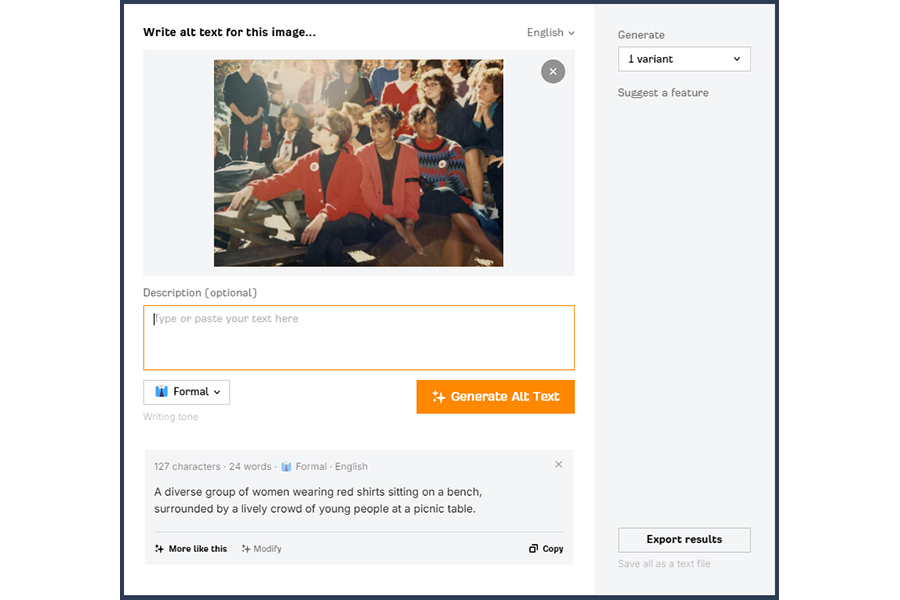
Automatically generated alt text describes it as “A diverse group of women wearing red shirts sitting on a bench, surrounded by a lively crowd of young people at a picnic table”.
The surrounding information a human might use to decide on the most appropriate alt text – a news article on the protests – isn’t available to this generator, so it focused on the visual information, misjudging the context and adding information that isn’t relevant to the purpose of the image, such as “picnic table”.
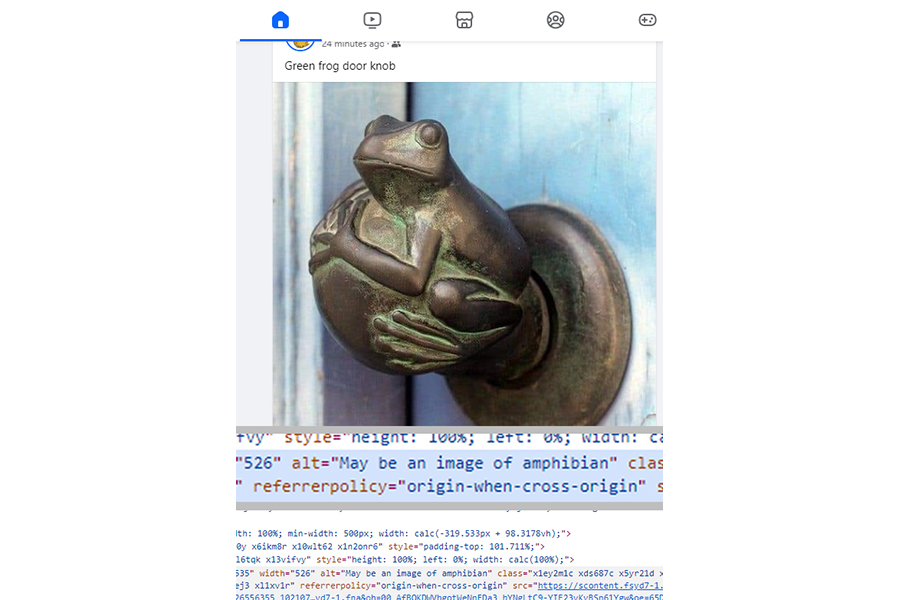
Photo: Facebook
){kind=link}
With this image, Facebook’s alt text generator ignored the text of a message: “Green frog door knob”, and concluded that this “May be an image of amphibian”, which is not untrue but doesn’t tell a screen reader user that it’s a door knob in the shape of a frog.
Photo: Cornell University arxiv
However, there are currently underway projects to teach machines to analyze surrounding text and other images on a web page (or social media post) and generate alternative text for a screen reader that equates to that which would be added by a human. With the kinds of technologies we’re talking about, this is by no means an insurmountable task.
This slide shows the analysis of a social media post that says “I check my mail daily. Today, I received 18 election flyers. Good lord. Make it stop. PS – be sure to vote. Hashtag California Primary”, with a photo of a hand holding multiple election flyers.
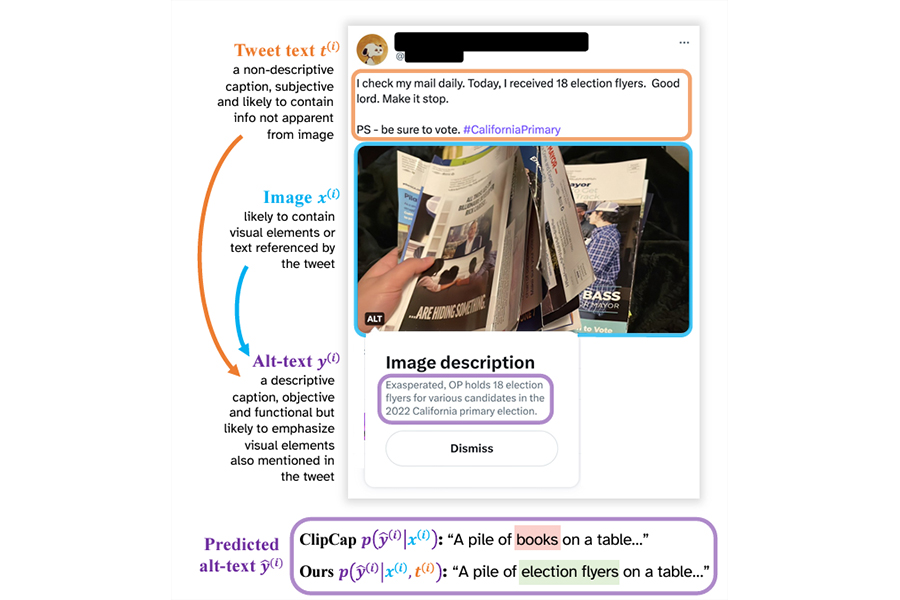
Photo: Cornell University arxiv (pdf)
Logic flows for deciding on the image content are then described, resulting in automatically generated alt text, “Exasperated OP holds 18 election flyers for various candidates in the 2022 California primary election”. The AI has correctly assessed image-relevant content to include in the alt text from the tweet text, including what “election flyers” means, what the hashtag refers to and the tone of the tweet.
In fact, it’s not unreasonable to expect that some AI alt text generators are already better at this than human beings. Anyone who’s audited more than a few websites knows that human-generated alt text is often variable at best.
That’s partly because the humans writing the alt text are not always the same people who produced the surrounding web content, and may not even understand the context very well, and partly also because humans can be overly verbose, opinionated, and judgmental.
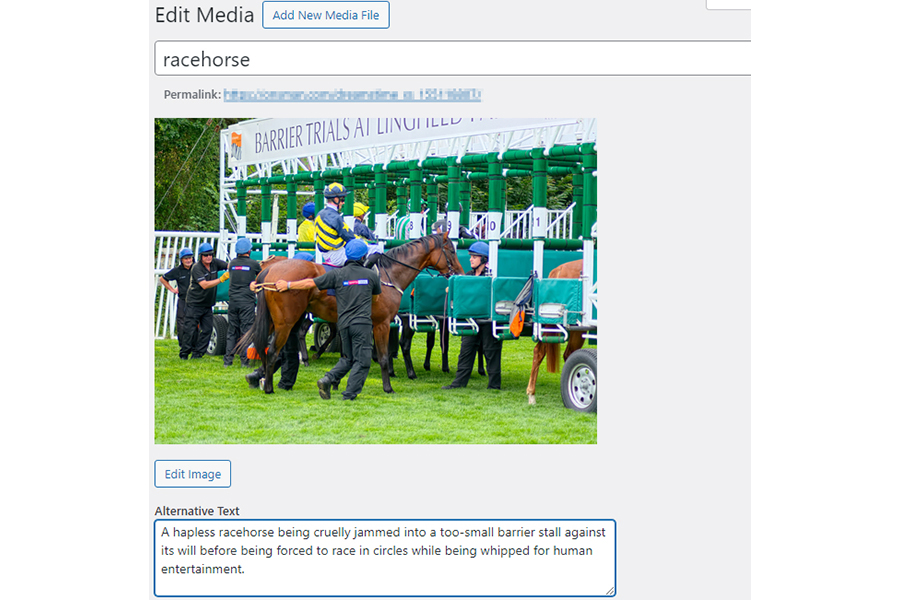
For the alt text of this photo of a racehorse entering the barrier before a race, a human wrote:
“A hapless racehorse being cruelly jammed into a too-small barrier stall against its will before being forced to race in circles while being whipped for human entertainment.”
This alt text was written for a sports news portal, not for a site protesting cruelty to animals.
In many ways, a machine working off a massive dataset may be better placed than a human to analyze an image’s context and choose a description that fits the purpose of the web content.
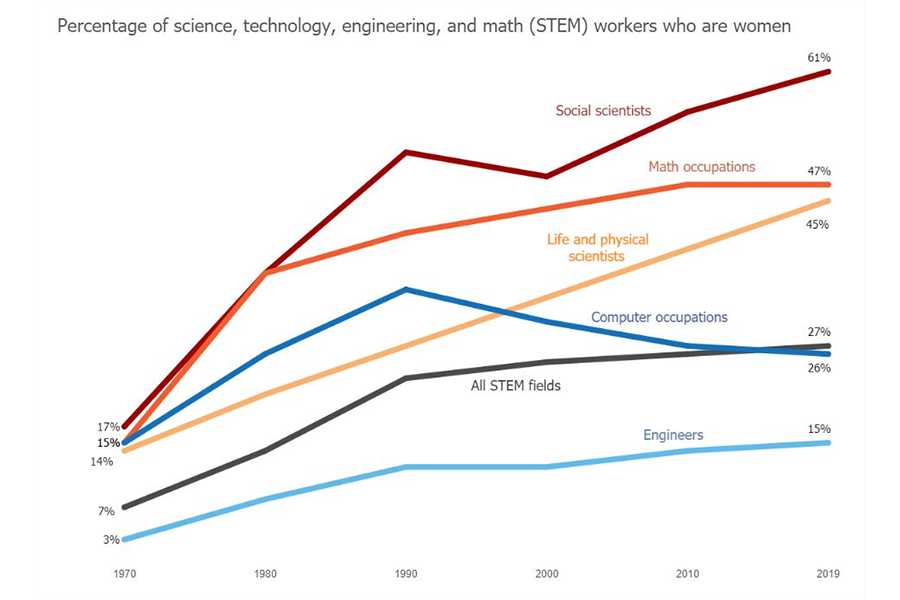
This extends to complex images, diagrams and illustrations. Charts and graphs visualize not just data, but relationships between data. Alt text generators can already describe these relationships, working off the original tabular data used to generate the images to create alt text such as “the rate of women entering the automobile engineering workforce in the USA has tripled in the last forty years, a higher rate than in all other industries and in most other geographic locations”.
I do have a caveat. There is a current generation of AI-powered alt generators that focus on search engine optimization rather than accessibility. Keyword stuffing is, of course, just a reflection of how many humans currently regard alt text – AI just automates it.
To successfully enhance accessibility, automated alt text generators could use something like this logic.
- Does the image have alt text?
- If alt text does exist, is it accurate and contextually appropriate?
- If existing alt text isn’t accurate and contextually appropriately, what should replace it?
- If alt text doesn’t exist, is the image purely decorative?
- If alt text doesn’t exist and the image is not purely decorative, is it described in surrounding or accompanying text?
- If the image is not decorative and not already described, what is the most contextually appropriate text to add to the alt attribute?
- The resulting alt text must be accurate, concise, and fit the context.
Based on current and forthcoming technology developments, that seems entirely doable, if not now, then very soon.
Nevertheless, there’s no reason purpose-specific AI tools can’t be used now to analyze an image and its context to calculate appropriate alt text. However, what if AI could be used to generate not just alt text it thinks is “right”, but alt text that it calculates to meet the needs of each user – every user, in every context.
That’s where AI is going.
Comments
RE: Manual editing of automated captions — YouTube has a graphical interface for caption editing. It’s a bit like an audio editing UI, with a timeline graph, and boxes of text you can move around to change timings, and edit the text itself. It’s a little quirky to use, but works quite well once you get used to it.
Good to know, James, thanks for pointing it out.
Readers of this article may be interested to see that the W3C published AI & the Web: Understanding and managing the impact of Machine Learning models on the Web on April 3 2024.
“This document proposes an analysis of the systemic impact of AI systems, and in particular ones based on Machine Learning models, on the Web, and the role that Web standardization may play in managing that impact.”